Kennedy Fire Trail: GPS course matching & timing algorithm
Here's a summary of the method I used to extract times from GPS data on the Kennedy Fire Trail run.
- First I defined a course. This was done with a series of "lines": line segments the riders needed to cross in a specified direction. This is in contrast to Strava's approach of defining a course via points. For matching, Strava treats the start and end point as special, requiring the activity to pass them with close proximity. Intermediate points need to be matched in a much cruder fashion, and only then a certain fraction of the points. My approach, however, required all intermediate "lines" to be crossed. I defined these points using latitude-longitude coordinate pairs, which are easily extracted from Google Maps (select point, right-click, "What's Here?").
- Split times were specified as pairs of lines, where the start line is 0, and the finish line is the last line. For example, my course had split times from 0 to 1 (an initial 40 meter sprint), from 0 to 2 (from the start to a flattish point just past halfway up the hill), from 2 to 3 (from this point to the bottom of a short descent), and from 3 to 4 (from this point to the finish a 1/4 mile away).
- Lines were defined with two points and a width: the first point a center point, the next point establishing a right-hand direction, and the width defining the distance to the right-hand boundary of the line in the direction of that second point. The left boundary of the line was defined in the opposite direction the same distance as the right point.
- Line crossings were determined by considering the rider trajectory on a segment-by-segment basis, where each segment was defined by adjacent points on the data record. The intersection of the course line and the trajectory segment was determined. It needed to fall within the bounds of both the line and the trajectory segment for a crossing to have occurred. The vector cross-product of the line with respect to the trajectory was then checked to make sure it was in the positive-altitude direction (line defined from center to right points, using a right-hand coordinate system). This was to check that the crossing was done in the correct direction.
- Line crossings were considered only if they occurred at the starting point, or any point up to including the one following the last line crossing (if any). Thus, the start line needed to be crossed first, then either the start line or the point following, etc. With this approach, the activity could repeat an earlier line crossing, but if so had to begin again with the line following.
- Timing was initiated each time the start line was crossed. I linearly interpolated this time from the data, which is a substantial improvement versus Strava, which simply takes the time of a point. With Strava this introduces large errors during Garmin "smart sampling" or periods of momentary signal loss, where time gaps may be a substantial number of seconds. With my method, as long as the trajectory can be reasonably reproduced and the speed is reasonably uniform during the time, the estimated crossing time is relatively independent of the sampling rate.
- Timing was completed each time the finish line was crossed. If earlier times had been determined (multiple laps of the course) only the shortest net time was retained. Memory of line crossings was reset each time the finish line was crossed, so if the finish line was crossed, the next line crossing (if any) had to be the starting line.
- Split timings were initiated each time the first line in the split was crossed.
- Split timings were recorded each time the second line in the split was recorded. If this occurred multiple times, only the fastest time was retained. Note if the course was traversed multiple times, a given split might not have been from the same "lap" as the final time. One rider on Kennedy rode twice on different bikes. He submitted only the data from the fastest run. Had he submitted a combined activity with both runs, even though he'd gotten the same final time, he might have gotten faster split times, had any of the faster split times occurred on the slower run.
It's simple, really. The key difficulty is setting up the course. But for "events", that's not a concern for a reasonable number of distinct checkpoints.
My code had one feature I didn't use at Kennedy: a time budget to get between adjacent checkpoints. I'll use this next year, when I'll set up a course which climbs multiple short hills, where I'll give riders a reasonable time to get from the top of one hill to the bottom of the next. As long as their time between these checkpoints is less than the budgeted time, no time will count towards the overall time. If more time is taken, the time budget will be subtracted from the time taken to connect those two lines. The idea here is to allow riders to proceed at a relaxed, safe pace, maybe even efficiently repair a flat tire, but not to allow riders to substantially rest, stop for meals, etc.
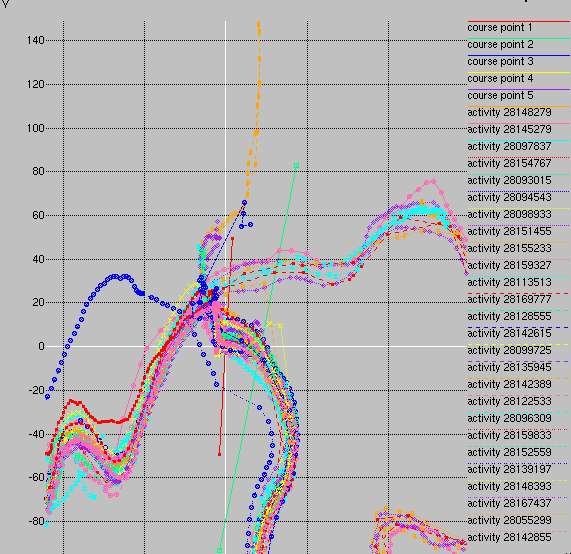
Plot showing subset of activities crossing the start line (red) and, subsequently the first checkpoint 40 meters later (green). The crossings must be from left-to-right, so those approaching on the road (higher stream) failed to trigger the start. Those moving to the right on the road would trigger the start but when subsequently moving right on the trail (lower stream) the start would be reset. The lines were generously defined (50 meter width for start, 100 meter width for first checkpoint) since the route is well-defined without short-cuts and failing to exclude valid rides was given a higher priority than rejecting data which was potentially low accuracy. Some anomalies in rider data are evident, such as the blue curve which loses signal briefly or else succumbs to Garmin "smart sampling" (281391197), but generally the data appear clean in the proximity of the line crossings, which helps explain the apparent good results which were attained with the first split time, despite it's short length. Strava would not have been reliable for such a short segment due to its lack of interpolation and its use of point-proximity rather than line-crossing as a criterion.
Comments