A look at GPS data from Low-Key Hillclimbs Week 4: Portola Valley Hills
This is another in a series of the Low-Key Hillclimbs Portola Valley Hills meta-climb. It was the second climb where Low-Key used custom timing code to extract rider times from GPS data. But it was by far the most complex, since instead of one climb where time was the difference between the time at the top and bottom, it was a series of 5 climbs where the times from each were added.
I did preliminary testing of the Portola Valley Hills course with 6 data sets of riders who had attempted to pre-ride the course. One did the climbs in the incorrect sequence, leaving 5 riders which the scoring code processed. I had no problem with these riders.
But it's a big difference between processing 5 data sets and processing 70.
Here I'll look at the GPS tracks I recorded for each of the climbs in the Portola Valley Hills.
First, the good. Here's plots for the three climbs ending at appropriately named Peak. The plots are x versus y, where x and y are the distance eastward and northward in meters or kilometers from the first checkpoint of the course. It's obvious which axes are in km and which are in meters.

Cervantes is blue, Golden Oak West is green, and Golden Oak East is red. These data look very good. There's one or two wayward data sets on each climb. The one deviant track on Cervantes appears to recover right at the finish line, which is to the right. Golden Oak West contains one slightly deviant trace, but it deviates only for one turn in the middle of the route, which is irrelevant for total timing. Golden Oak East has only one trace where there appears to be a chance for an error of any significance.
Now the bad. Summit Spring is next.

The start is to the right, the finish to the left. There's at least 5 tracks which deviate substantially from the main "cloud" of 65. In several cases I applied manual finish line shifts to accomodate these deviant trajectories. The rest look fairly good. Note even small distance shifts on Summit Spring can yield time shifts of several seconds. But that's part of the deal with this week's climb. In the name of diversity we decided to live with a bit less precision.
Finally, the ugly. Joaquin.
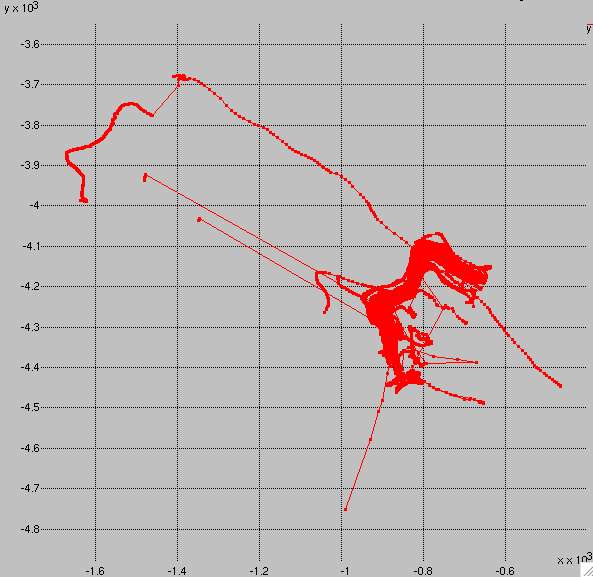
Joaquin was a mess. Several riders were diverted substantially to the WNW. One rider's GPS launched a start-line-piercing spike to the SSW. Then there's that strange trace shooting out to the SE. The finish area is arguably manageable, but the start area is a total wreck. I saw this plot and I threw in the towel. It would be too much contamination of the final results. I neutralized Joaquin.
Before you say "what was he thinking??"", here's the data from the test riders, shown in green, plotted versus the event data, shown in red. The plot is zoomed in relative to the previous one, so the extreme outliers on the red data are truncated. Sure, the green data aren't great. There's some lateral spread. But it's all quite consistent with the spirit of the event: accuracy to within 5 seconds or so on each climb.
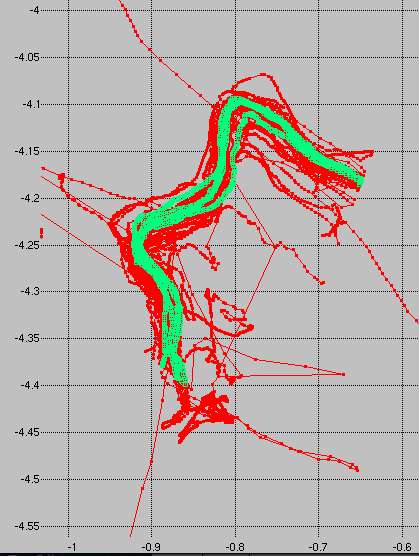
I may look more closely at these data in the future. In particular I am interested in whether the outliers in this plot are associated with a particular GPS unit. To do that I need to scrape the HTML from Strava, using the URLs for the rider activities, to get the computer type. It's not provided in the V3 API. It's slightly complicated by authentication, but that's another matter.
In any case, the moral of the story is processing GPS data from a diverse group of hillclimb enthusiasts is a nontrivial task. It's critical to identify problem cases like Joaquin before starting a competition. An alternative is to use altitude data in conjunction with position to do timing. I didn't investigate that option, and indeed I didn't even record altitude numbers when I had then upload their rides to lowkeyhillclimbs.com. But the deal with altitude is it may be recorded directly, like with the Garmin Edge 500-800, or may be determined from map data using the recorded position, as it is typically with phones and with the Garmin Edge 200. So using altitude only provides independent information if it is derived from a unit which measures altitude directly.
So next time, we pick hills where the start and finish have nice clear views of the sky.
But I received one suggestion which was very promising. Instead of a total time based on a sum of indidivual times for each of every climb on a course, give riders one or more "throw-aways". Then if they have GPS issues on one climb and fail to match the course, that becomes a throw-away. If a rider matches all climbs on the course, throw-aways are those climbs contributing least well to his total score. Riders would then be given a time for throw-away climbs relative to the average and standard deviation rider time for that climbs and how they compared to the average and standard deviation of times on their counting climbs. This would work, but would require more coding. Maybe I'll try something like that on the Portola Valley data set, as a trial for something next year.



Comments
They did this by heading up Alpine beyond Joaquin, pulling a u-turn, and hitting the climb with speed.
Before heading up Alpine past Joaquin, could they have crossed the start line of the segment by accident?
It seems possible that moving the start line of this segment a few dozen meters down Alpine Road could solve these problems.
I'm sure a lot of people also took a break at the base of Joaquin after riding up Alpine -- my Garmin seems to wander whenever I take a break (I know this because it says I'm going 1 or 2 mph when I'm standing still).
The other idea I was thinking of was using altitude versus distance as a proxy timing trigger. I added altitude to the data I have riders upload from their Strava activities, as well as Strava distance, which filters for jumps in position (versus calculating distance from latlng). It's good to have backup systems, especially since the unit which seems to cause the most problem with latlng (Garmin Edge 500) has good altitude (GPS calibrated barometric).
Now I'm glad it was relegated.