testing Strava segment timing reliability
DC Rainmaker recently did an interesting study of the accuracy of GPS units. He mounted eight different GPS computers on the handle of surveyer's measurement wheel then walked, ran, or rode various courses, comparing the measured results (Part 1, Part 2). The GPS units tended to disagree on how far he'd gone, although usually the results were consistent with the claimed positional accuracy of the units.
I suggested he use the data to test Strava reproducibility in segment timing. No luck there, but I did find that a friend of mine has been in the habit of riding with a Garmin Edge 500 mounted alongside a Garmin Edge 800 on his rides. We have a mutual friend who works for Garmin, so he's doing this to compare the two.
I asked him for data from three of his rides. I then created two new accounts on Strava and uploaded the data from his Edge 500 into one, and from the Edge 800 into the other. The new accounts are necessary because Strava rejects what appear to be duplicate rides from the same account. I made these rides private to avoid contaminating the historical record, since he'd already uploaded data using his personal account. Then I created a spreadsheet with all of the segments for each of the three rides.
The Edge 800 data yielded 58 matched segments, while the Edge 500 yielded 56 matched segments. The two segments matched to the Edge 800 data but missed in the Edge 500 data were "West Alpine Road Start of Climb" and "West Alpine Road Portola State Park Road to Finish". Obviously there had been an issue with the Edge 500 data on Alpine Road. However, the Edge 500 data did trigger the "West Alpine Road Alpine Creek to Peak" segment. West Alpine Road is a relatively complex climb and has had an extraordinary number of segments defined for it: of the 56 total segments matched to both data sets, nine are on Alpine Road. And these are in addition to the two Alpine Road segments which were assigned only to the Edge 800 data.
For each segment I subtracted the claimed time for the segment derived for the Edge 500 data from that derived for the Edge 800 data.
Before I show the graph, I should add I expected some difference. Garmins sample at one or two second intervals. Strava interpolates on these data points, but interpolations can only do so well, so I'd expect an error of around 1 second on the start time and around 1 second on the finish time, so even if everything's perfect, an error of ±2 seconds is about the best I'd anticipate.
There's other errors, of course. The GPS signal is only good to around 10 meter accuracy. But these are units with essentially the same electronics and the same algorithms looking at a signal within 10 cm of each other. So while the general positional error of the GPS signal should add up to around 10 meters of uncertainty to the start and stop position, since this positional error should affect both computers close to the same. But since bikes move at around 5 meters per second up hill, a 10 meter error at either the top or the bottom along the direction of travel could create another two seconds or so of variation in the segment timing.
Then there's the problem that the segment was defined with data which was also subject to noise. You'd like to believe there's an imaginary line across the road defining the start and end of a segment but the reality is the virtual line, even if your GPS is perfect, is slanted. So if your position in the road varies, or if the GPS signal varies your trajectory to the left or right, that will affect at what point you intersect these virtual start and finish lines. This could be another two seconds or so, similar to the error from longitudinal position error, off the start and finish. But again this error should be relatively smaller because we're considering two GPS units on the same handlebars at the same time.
So worst case I have the following error estimates for ride-to-ride variation:
I assume these errors are uncorrelated so I take the root-mean-squared-sum and get around 4 seconds typical variability for ride-to-ride variations, but less than that for two GPS units mounted on the same handlebars on the same ride... let's say 2 seconds.
So what's the data show? Here's the results:
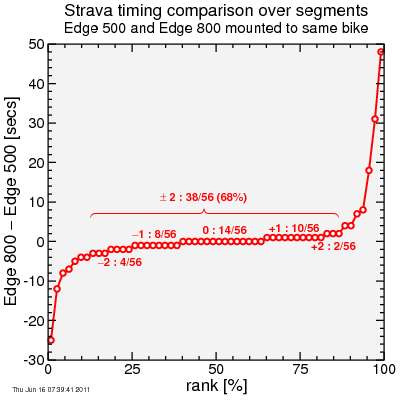
If I look at the mid-range of the distribution, my estimate was spot-on: errors are typically between ‒2 and +2 seconds, without evident bias between the two data sets. However, the devil here is in the tails. A significant number of segment timings have far worse errors.
These segments, it turns out, are all either on West Alpine Road or on Old La Honda Road. The top of Old La Honda Road, in particular, is notorious for terrible GPS signal quality due to the trees and terrain creating confusion from signal reflection. But Strava's algorithm is relatively forgiving, and so assigns segment times anyway.
Here are the worst offenders where the Edge 800 reported shorter times:
Wow -- 25 seconds on that first Old La Honda segment!
And here's the culprit segments where the Edge 500 reported shorter times:
This one's even better -- the West Alpine segment has a whopping 48 second disagreement. It's as if the Edge 500 had dropped the 800 with enough of a gap to get out of sight on those final turns... And curiously Old La Honda data actually appears at both ends of this range, demonstrating what a problem child Old La Honda can be.
So it may be on most segments the Garmin-Strava link does fairly well: within a handful of seconds. But on problematic segments the error can be profound, enough to radically change rankings.
Perhaps Strava should tighten up the criteria by which it considers rides to be a match to segments. This would result in users complaining that they'd ridden a segment but not gotten credit. But on the other hand it would improve the integity of the KOM rankings for these difficult segments. An alternative would be to flag marginally matching data on the rankings, so it becomes clearer that the results are questionable.
I suggested he use the data to test Strava reproducibility in segment timing. No luck there, but I did find that a friend of mine has been in the habit of riding with a Garmin Edge 500 mounted alongside a Garmin Edge 800 on his rides. We have a mutual friend who works for Garmin, so he's doing this to compare the two.
I asked him for data from three of his rides. I then created two new accounts on Strava and uploaded the data from his Edge 500 into one, and from the Edge 800 into the other. The new accounts are necessary because Strava rejects what appear to be duplicate rides from the same account. I made these rides private to avoid contaminating the historical record, since he'd already uploaded data using his personal account. Then I created a spreadsheet with all of the segments for each of the three rides.
The Edge 800 data yielded 58 matched segments, while the Edge 500 yielded 56 matched segments. The two segments matched to the Edge 800 data but missed in the Edge 500 data were "West Alpine Road Start of Climb" and "West Alpine Road Portola State Park Road to Finish". Obviously there had been an issue with the Edge 500 data on Alpine Road. However, the Edge 500 data did trigger the "West Alpine Road Alpine Creek to Peak" segment. West Alpine Road is a relatively complex climb and has had an extraordinary number of segments defined for it: of the 56 total segments matched to both data sets, nine are on Alpine Road. And these are in addition to the two Alpine Road segments which were assigned only to the Edge 800 data.
For each segment I subtracted the claimed time for the segment derived for the Edge 500 data from that derived for the Edge 800 data.
Before I show the graph, I should add I expected some difference. Garmins sample at one or two second intervals. Strava interpolates on these data points, but interpolations can only do so well, so I'd expect an error of around 1 second on the start time and around 1 second on the finish time, so even if everything's perfect, an error of ±2 seconds is about the best I'd anticipate.
There's other errors, of course. The GPS signal is only good to around 10 meter accuracy. But these are units with essentially the same electronics and the same algorithms looking at a signal within 10 cm of each other. So while the general positional error of the GPS signal should add up to around 10 meters of uncertainty to the start and stop position, since this positional error should affect both computers close to the same. But since bikes move at around 5 meters per second up hill, a 10 meter error at either the top or the bottom along the direction of travel could create another two seconds or so of variation in the segment timing.
Then there's the problem that the segment was defined with data which was also subject to noise. You'd like to believe there's an imaginary line across the road defining the start and end of a segment but the reality is the virtual line, even if your GPS is perfect, is slanted. So if your position in the road varies, or if the GPS signal varies your trajectory to the left or right, that will affect at what point you intersect these virtual start and finish lines. This could be another two seconds or so, similar to the error from longitudinal position error, off the start and finish. But again this error should be relatively smaller because we're considering two GPS units on the same handlebars at the same time.
So worst case I have the following error estimates for ride-to-ride variation:
- 1 second at start due to sampling time
- 1 second at finish due to sampling time
- 2 second at start due to longitudinal position errors
- 2 seconds at finish due to longitudinal position errors
- 2 seconds at start due to transverse position errors
- 2 seconds at finish due to transverse position errors
I assume these errors are uncorrelated so I take the root-mean-squared-sum and get around 4 seconds typical variability for ride-to-ride variations, but less than that for two GPS units mounted on the same handlebars on the same ride... let's say 2 seconds.
So what's the data show? Here's the results:
If I look at the mid-range of the distribution, my estimate was spot-on: errors are typically between ‒2 and +2 seconds, without evident bias between the two data sets. However, the devil here is in the tails. A significant number of segment timings have far worse errors.
These segments, it turns out, are all either on West Alpine Road or on Old La Honda Road. The top of Old La Honda Road, in particular, is notorious for terrible GPS signal quality due to the trees and terrain creating confusion from signal reflection. But Strava's algorithm is relatively forgiving, and so assigns segment times anyway.
Here are the worst offenders where the Edge 800 reported shorter times:
climb delta INTEGRATE_Performance_Fitness_OLH_Climb -25 OLH_Mile_3_to_End -12 OLH_(LowKey) -8 Arastradero/Alpine_-_Portola_-_Wed_Valley_Ride -7 Old_La_Honda_(bridge_front_to_stop_sign) -5 Old_La_Honda_(Bridge_to_Mailboxes) -4 West_Old_La_Honda_Descent -4
Wow -- 25 seconds on that first Old La Honda segment!
And here's the culprit segments where the Edge 500 reported shorter times:
climb delta West_Alpine_-_full_length 4 Old_La_Honda_Mile_3 4 OLH_-_Mile_2_to_3 7 West_Alpine_-_First_Half 8 West_Alpine—Alpine_Creek_to_Portola_SP_Rd 18 W_Alpine_climb_-_Alpine_Creek_to_2nd_switchback 31 West_Alpine_-_Alpine_Creek_to_peak_(RR_gate2) 48
This one's even better -- the West Alpine segment has a whopping 48 second disagreement. It's as if the Edge 500 had dropped the 800 with enough of a gap to get out of sight on those final turns... And curiously Old La Honda data actually appears at both ends of this range, demonstrating what a problem child Old La Honda can be.
So it may be on most segments the Garmin-Strava link does fairly well: within a handful of seconds. But on problematic segments the error can be profound, enough to radically change rankings.
Perhaps Strava should tighten up the criteria by which it considers rides to be a match to segments. This would result in users complaining that they'd ridden a segment but not gotten credit. But on the other hand it would improve the integity of the KOM rankings for these difficult segments. An alternative would be to flag marginally matching data on the rankings, so it becomes clearer that the results are questionable.



Comments
To Richard: I completely agree.
I believe a sizable factor in the deviations are the start/finish points of the underlying data behind the segment (the segment data is just the data from the original ride from which the segment was defined). The ends could be a bit off the normal path of the riders, so the matching is more irregular.
We also have issues when segments start or finish points are on tight switch-backs, in which case your start or finish could match to similar point further up or down the road.
The good news is that we're working on both of these issues. Eventually we'll have better tools to define start and finish lines on segments, beyond just finish points, allowing more accurate interpolation of the actual start/finish points on your rides. We also have some ideas on how to address the switchback issues.
Of course, as you point out, given the accuracy of GPS, it will never be perfect. I'm not sure we'll ever be in a position to know who pipped who at the finish line of a segment! The +/- 2 seconds is likely a reasonable target.
Thanks again for the post!
-Mark
Ultimately, if people get that bent out of shape about a potential data error, you should be getting paid for your result, or you should just ride faster and worry more about when Chris Phipps will take your segment anyway...
Just kidding, sort of, happy F'in Friday.
Mark: Thanks for the comments!
Top of OLH is a mess for GPS. A friend just posted this:
http://app.strava.com/rides/773628
two reps of OLH.
On this morning's ride up Kings, I'd love to believe the Strava report of 25:59, but my manual lap timer shows 26:17. That's a huge difference for timing points that shouldn't be tough to define (Tripp Road, which I assume someone set as the sign itself on the right-hand side heading up Kings, and... what? Looking at the segment, it appears to end a bit prematurely.
http://www.strava.com/activities/76157048#1521397209
And that explains the shorter Strava time. So do I add to the confusion and create an official Tuesday/Thursday-morning segment?
I need one of those "Strava made me dope" T-shirts...
I have Perl scripts I use for timing certain weeks of the Low-Key Hillclimbs where it's impractical to do organized hand-timed events. There I use a different model, hardly original: I use lines instead of points and interpolate the time the GPS track passes through the line segment. I then hand-place key checkpoints along the way to make sure the rider did the whole climb. Lines provide for timing precision while allowing for GPS to deviate laterally. Points, used by Strava without interpolation, are a much blunter instrument. Of course my model requires more care in segment definition, but interpolation is something Strava could do now -- it would just take a few extra CPU cycles.
http://mroek.blogspot.no/2015/09/why-strava-segment-matching-and-timing.html
http://mroek.blogspot.no/2015/10/why-doesnt-strava-do-proper.html
I'd really like for Strava to get this fixed, so I'm trying to surface this issue again, and as it is something you've also written about quite a few times, I thought I'd post the links here.